



逆向攻防世界CTF系列11-maze
逆向攻防世界CTF系列11-maze
迷宫问题:迷宫问题 - CTF Wiki (ctf-wiki.org)
64位无壳
__int64 __fastcall main(__int64 a1, char **a2, char **a3){
const char *v3; // rsi
signed __int64 v4; // rbx
signed int v5; // eax
char v6; // bp
char v7; // al
const char *v8; // rdi
__int64 v10; // [rsp+0h] [rbp-28h]
v10 = 0LL;
puts("Input flag:");
scanf("%s", &s1, 0LL);
if (strlen(&s1) != 24 || (v3 = "nctf{", strncmp(&s1, "nctf{", 5uLL)) || *(&byte_6010BF + 24) != 125){
LABEL_22:
puts("Wrong flag!");
exit(-1);
}
v4 = 5LL;
if ( strlen(&s1) - 1 > 5 ) {
while ( 1 ){
v5 = *(&s1 + v4);
v6 = 0;
if ( v5 > 78 ){
v5 = (unsigned __int8)v5;
if ( (unsigned __int8)v5 == 79 ){
v7 = sub_400650((char *)&v10 + 4, v3);
goto LABEL_14;
}
if ( v5 == 111 ){
v7 = sub_400660((char *)&v10 + 4, v3);
goto LABEL_14;
}
}
else{
v5 = (unsigned __int8)v5;
if ( (unsigned __int8)v5 == 46 ){
v7 = sub_400670(&v10, v3);
goto LABEL_14;
}
if ( v5 == 48 ){
v7 = sub_400680(&v10, v3);
LABEL_14:
v6 = v7;
goto LABEL_15;
}
}
LABEL_15:
v3 = (const char *)HIDWORD(v10);
if ( !(unsigned __int8)sub_400690(asc_601060, HIDWORD(v10), (unsigned int)v10) )
goto LABEL_22;
if ( ++v4 >= strlen(&s1) - 1 )
{
if ( v6 )
break;
LABEL_20:
v8 = "Wrong flag!";
goto LABEL_21;
}
}
}
if ( asc_601060[8 * (signed int)v10 + SHIDWORD(v10)] != 35 )
goto LABEL_20;
v8 = "Congratulations!";
LABEL_21:
puts(v8);
return 0LL;
}
- 开头必须是
nctf{,总长24,第25位最后一位是不是”}” 125='}'

右键char,发现四个字符
这里(_DWORD *)是对v6进行强制类型转化,,然后在提领指针,WORD占2个字节,DWORD占4个字节。
shift+f12找到看看,发现


再看之前那张图,当为'O'时,点进函数看看,
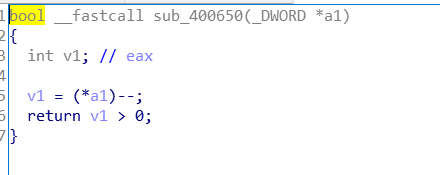
在16位的CPU中,一个字刚好为两个字节,而32位CPU中,一个字是四个字节。若以字为单位,向上还有双字(两个字),四字
解题1
好吧,上面分析的很乱,这里有个坑点就是,看了wp才发现,v10其实是两个变量,我一直做不出来的原因就是不太懂伪代码中的那四个函数,怎么得出的上下左右,明明都是v10,第二就是dword(v10)跟普通的int(v10)有什么区别,第三就是太相信伪代码了,反编译的结果也有可能具有误导性。
这里我ida版本是7.0,我切换8.3的伪代码如下:

这里很清晰的有v9和v10之分

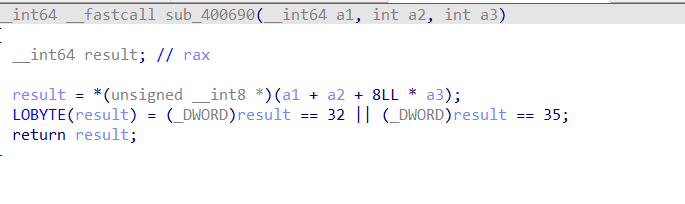
可以得知a3也就是v9是行,asc_601060是迷宫,v10是列,返回去
sub_400670:向上.
sub_400680:向下0
O:向左
o:向右
可以从上面得知一行是8个数据

******
* * *
*** * **
** * **
* *# *
** *** *
** *
********

到达#就通关了
根据前面我们可以得到flag:nctf{o0oo00O000oooo..OO}
解法2
有时我们一下子不能发现伪代码的坑点,因此我们要学会尝试分析汇编语言,这里提供第二种理解方式
即使只有一个变量v10我们仍能分析出,每行拥有8个数据
得到迷宫:
******
* * *
*** * **
** * **
* *# *
** *** *
** *
********
结果又发现了一个新知识,每次反编译的结果好像是不同的

发现和之前的结果不同。

HIWORD是High Word的缩写,作用是取得某个4字节变量(即32位的值)在内存中处于高位的两个字节,即一个word长的数据
LOWORD是Low Word的缩写,作用是取得某个4字节变量(即32位的值)在内存中处于低位的两个字节,即一个word长的数据
发现了HIWORD这个细节,是高字
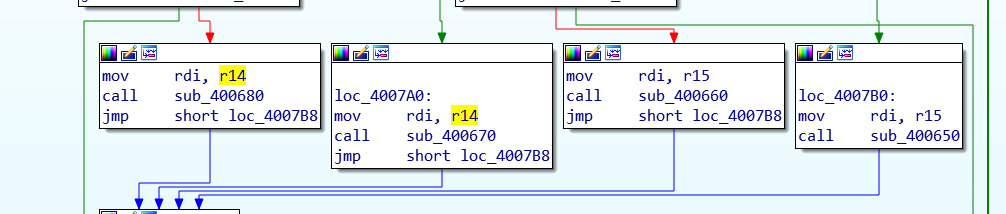
r14是sub_80和70
r15是sub_60和50

r14是低位,与上对照,R14是行,80和70是行,0,.是操作行的
Oo是操作列的
可以得到结果flag
